라이브러리 불러오기
# 기본 라이브러리 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns베이직 문항
1. Iris 데이터셋에서 Logistic Regression 분류
Iris 데이터셋을 사용하여 Logistic Regression 모델을 학습시키고, 정확도(accuracy)를 계산하세요
풀이과정
- 데이터 불러오기
- test, train 데이터 나누기
💡 train_test_split에서 stratify의 역할
클래스의 분포 비율을 맞춰서 데이터를 나눠준다.


→ stratify 유무에 따라 accuracy에 차이가 있다. 교차검증 정확도가 1인 것 보다는 , 0.933이 더 신뢰가능한 수준이라고 판단해 stratify를 적용함.
그렇다면, iris에서는 왜 층화추출 옵션이 필요할까?

그래프 그리기
plt.figure(figsize=(16,9))
plt.subplot(1,2,1)
sns.histplot(iris_y_train, kde=True, color = 'green')
plt.title('train')
plt.subplot(1,2,2)
sns.histplot(iris_y_test, kde=True, color = 'pink')
plt.title('test')층화추출의 경우 주로 클래스가 불균형하게 분포되어 있고 데이터 양이 적을 때 권장된다.
iris 데이터의 경우 데이터의 개수가 총 105개로 일반적인 데이터 셋에 비하면,
데이터의 수가 많이 작은편에 속한다.

그렇기 때문에 stratify를 이용해주면 비교적 고른 분포를 가지도록
데이터를 나눠줄 수 있게 된다.
- Grid Search 진행 - 더 좋은 하이퍼파라미터 찾기


Grid Search 진행 결과, max_iter를 100으로 하고 solver를 sag로 했을 때 교차검증 정확도가 0.9333에서 0.9778로 올라갔다.
- 최종 accuracy 계산
제출답안
# 데이터 불러오기
from sklearn.datasets import load_iris
iris = load_iris()
iris_X, iris_y = iris.data, iris.target
# test, train 데이터 나누기
from sklearn.model_selection import train_test_split
iris_X_train, iris_X_test, iris_y_train, iris_y_test = train_test_split(iris_X, iris_y,
test_size= 0.3,
shuffle = True,
stratify=iris_y,
random_state= 42)
# 함수 불러오기 및 모델에 구조 넣기
from sklearn.linear_model import LogisticRegression
model_lor = LogisticRegression(random_state=42)
# 모델 적합
model_lor.fit(iris_X_train,iris_y_train)
# accuracy 계산하기 model_lor
from sklearn.metrics import accuracy_score
iris_pred_test = model_lor.predict(iris_X_test)
accuracy = accuracy_score(iris_y_test,iris_pred_test)
print(f'model_lor의 교차검증 정확도는 {accuracy:.4f} 입니다.') ## model_lor의 교차검증 정확도는 0.9333 입니다.
# Grid Search
from sklearn.model_selection import GridSearchCV
params = {'solver' : ['newton-cg','lbfgs','liblinear','sag','saga'],
'max_iter' : [10,50,100]}
grid_lor = GridSearchCV(model_lor, param_grid = params, scoring='accuracy', cv = 5)
grid_lor.fit(iris_X_train, iris_y_train)
# Grid Search 에서 찾은 best 조합으로 model_lor2 생성
iris_best_max_iter = grid_lor.best_params_['max_iter']
iris_best_solver = grid_lor.best_params_['solver']
model_lor2 = LogisticRegression(random_state=42, max_iter = iris_best_max_iter, solver = iris_best_solver)
model_lor2.fit(iris_X_train,iris_y_train)
# accuracy 계산하기 model_lor2
iris_pred_test2 = model_lor2.predict(iris_X_test)
accuracy2 = accuracy_score(iris_y_test,iris_pred_test2)
print(f'model_lor2의 교차검증 정확도는 {accuracy2:.4f} 입니다.') ## model_lor2의 교차검증 정확도는 0.9778 입니다.2. Boston 주택 가격 Linear Regression 예측
Boston 주택 가격 데이터셋을 사용하여 주택 가격을 예측하는 회귀 모델을 만드세요.
풀이과정
- 데이터 불러오기
- train, test 데이터 나누기 - 총 20640개의 데이터, stratify X(14448, 6192로 나눔)
- 모델 적합하기
- test 데이터로 mse 계산하기
제출답안
# 데이터 불러오기
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
housing_X, housing_y = housing['data'], housing['target']
# test, train 데이터 나누기
from sklearn.model_selection import train_test_split
housing_X_train, housing_X_test, housing_y_train, housing_y_test = train_test_split(housing_X, housing_y,
test_size= 0.3,
shuffle = True,
random_state= 42)
# 함수 불러오기 및 모델에 구조 넣기
from sklearn.linear_model import LinearRegression
model_lr= LinearRegression()
# 모델 적합
model_lr.fit(housing_X_train, housing_y_train)
# mse 계산하기
from sklearn.metrics import mean_squared_error
housing_pred = model_lr.predict(housing_X_test)
mse = mean_squared_error(housing_y_test, housing_pred).round(4)
print(f'mse는 {mse}입니다.') ## mse는 0.5306입니다.
3. iris데이터 DecisionTree로 분류
Iris 데이터셋을 사용하여 DecisionTree 모델을 학습시키고, 정확도(accuracy)를 계산하세요
풀이과정
- 데이터 불러오기/ train, test 데이터 나누기 (생략)
- 함수 불러오고 fitting하기
→ max_depth를 조정하며 최적의 max_depth 값을 찾음.

max_depth를 4로 지정했을때보다 5로 지정했을 때 정확도가 높아졌으며, 5로 지정했을 때와 6을 지정했을 때 정확도가 개선되지 않았다. 따라서 가장 효율적인 max_depth값은 5이다.
from sklearn.tree import DecisionTreeClassifier, plot_tree
model_dt_max_4 = DecisionTreeClassifier(random_state=42, max_depth=4)
model_dt_max_5 = DecisionTreeClassifier(random_state=42, max_depth=5)
model_dt_max_6 = DecisionTreeClassifier(random_state=42, max_depth=6)
# fitting
model_dt_max_4.fit(iris_X_train,iris_y_train)
model_dt_max_5.fit(iris_X_train,iris_y_train)
model_dt_max_6.fit(iris_X_train,iris_y_train)
# accuracy 계산 - max_depth = 4
iris_dt_pred_4 = model_dt_max_4.predict(iris_X_test)
accuracy_dt_4 = accuracy_score(iris_y_test,iris_dt_pred_4)
print(f'Decision Tree에서 max_depth를 4로 줬을 때 교차검증 정확도는 {accuracy_dt_4:.4f} 입니다.')
# accuracy 계산 - max_depth = 5
iris_dt_pred_5 = model_dt_max_5.predict(iris_X_test)
accuracy_dt_5 = accuracy_score(iris_y_test,iris_dt_pred_5)
print(f'Decision Tree에서 max_depth를 5로 줬을 때 교차검증 정확도는 {accuracy_dt_5:.4f} 입니다.')
# accuracy 계산 - max_depth = 6
iris_dt_pred_6 = model_dt_max_6.predict(iris_X_test)
accuracy_dt_6 = accuracy_score(iris_y_test,iris_dt_pred_6)
print(f'Decision Tree에서 max_depth를 6로 줬을 때 교차검증 정확도는 {accuracy_dt_6:.4f} 입니다.')- 의사결정나무 그리기

from sklearn.tree import plot_tree
# 의사결정나무 그리기
X_features = iris.feature_names
iris_class = iris.target_names
plt.figure(figsize=(16,9))
plot_tree(model_dt_max_5,
feature_names=X_features,
class_names=iris_class, #
filled = True # 의사결정 나무 안의 사각형을 채우기
)
plt.show()- test 데이터로 모델의 accuracy 계산하기
제출답안
# 라이브러리 불러오기
from sklearn.tree import DecisionTreeClassifier
# 모델 넣기
model_dt = DecisionTreeClassifier(random_state=42, max_depth=5)
# fitting
model_dt.fit(iris_X_train,iris_y_train)
# accuracy 계산
iris_dt = model_dt.predict(iris_X_test)
accuracy_dt = accuracy_score(iris_y_test,iris_dt)
print(f'Decision Tree에서 교차검증 정확도는 {accuracy_dt:.4f} 입니다.')
## Decision Tree에서 교차검증 정확도는 0.9333 입니다.챌린지 문항
4. 타이타닉 데이터를 랜덤포레스트 분류기로 생존여부를 예측하세요
- 데이터의 특성 중 다음 특성들만 사용하세요 ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare"]
- 성능은 accuracy로 평가
풀이과정
- 데이터 불러오기
- 'SibSp' + 'Parch' = 'Family' 변수 생성

- Fare 이상치 제거


Fare가 500이 넘는 경우 이상치 발견
→ 건수가 3개 밖에 되지 않아서 삭제하기로 함.
sns.histplot(data = titanic, x= 'Fare', kde = True)
plt.title('Distribution of Fare')
# Fare 이상치 제거 - IQR
mask = (titanic['Fare']< 512)
titanic = titanic[mask]
sns.histplot(data = titanic, x= 'Fare', kde = True, color = 'red')
plt.title('Distribution of Fare (outlier removed)')- train, test 데이터 나누기
- 전처리
- 결측치 확인 결과 'Age' 컬럼에 177개의 결측치가 존재하는 것을 확인 → 평균으로 채우기
- Pclass(1,2,3)와 Sex('male', 'female')을 라벨 인코딩
- 표준화(Fare), 정규화(Age, Family)
- 함수 불러오고 fitting하기(랜덤 포레스트)
- test 데이터로 모델의 accuracy 계산하기 - RandomForest 모델의 accuracy는 0.933입니다.
제출답안
# 데이터 불러오기
url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
titanic = pd.read_csv(url)
# SibSp + Parch = Family
titanic['Family'] = titanic['SibSp']+titanic['Parch'] + 1
# test, train 데이터 나누기
from sklearn.model_selection import train_test_split
titanic_X_train, titanic_X_test, titanic_y_train, titanic_y_test = train_test_split(titanic_X, titanic_y,
test_size= 0.3,
shuffle = True,
stratify=titanic_y,
random_state= 42)
# 전처리
# 결측치 처리 함수
def preprocess_missing(df):
# Age : 결측값 (714개) 평균값으로 채우기
age_mean = df['Age'].mean()
df['Age'] = df['Age'].fillna(age_mean)
preprocess_missing(titanic_X_train)
preprocess_missing(titanic_X_test)
# 인코딩
def label_encoder(df):
from sklearn.preprocessing import LabelEncoder
# Pclass 라벨 인코딩
le1 = LabelEncoder()
df['Pclass_le'] = le1.fit_transform(df['Pclass'])
# Sex 라벨 인코딩
le2 = LabelEncoder()
df['Sex_le'] = le2.fit_transform(df['Sex'])
label_encoder(titanic_X_train)
label_encoder(titanic_X_test)
# 스케일링
def preprocess_scaling(df):
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 표준화 : Fare
sd_sc = StandardScaler()
df['Fare_sd_sc'] = sd_sc.fit_transform(df[['Fare']])
# 정규화 : Age
mm_sc = MinMaxScaler()
mm_sc.fit(df[['Age','Family']])
df[['Age_mm_sc','Family_mm_sc']] = mm_sc.transform(df[['Age','Family']])
preprocess_scaling(titanic_X_train)
preprocess_scaling(titanic_X_test)
# Random Forest
from sklearn.ensemble import RandomForestClassifier
model_rf = RandomForestClassifier(random_state=42)
# fitting
titanic_X_train2 = titanic_X_train.iloc[:,5:]
model_rf.fit(titanic_X_train2, titanic_y_train)
# 평가하기
from sklearn.metrics import accuracy_score
X_test = titanic_X_test.iloc[:,5:]
y_pred = model_rf.predict(X_test)
accuarcy = accuracy_score(titanic_y_test, y_pred)
print(f'RandomForest 모델의 accuracy는{accuracy: .3f}입니다.')5. iris 데이터를 이용하여 클러스터링을 수행하고 시각화 하세요
- 클러스터의 개수는 3개로 설정한다.
- 클러스터의 결과를 시각화 하기 위해 데이터의 첫번째 특성을 X축, 두번째 특성을 Y축으로 하는 산점도(scatter) 그리세요!
풀이과정
- 데이터 불러오기
- array 타입이기 때문에 scatter plot을 그리기 위해서는 데이터를 펼쳐줘야 한다!
- 정규화를 하는 경우 성능이 좋아지는지 판단하기 위해 MinMaxScaler를 이용한 비교군 iris_X_mm_sc 도 만들어준다.
- K-Means Clustering
- 정규화된 모델(MinMaxScaler) - inertia는 4.115이고, 실루엣 계수는 0.444이다.
- 정규화되지 않은 경우 - inertia는 37.051이고, 실루엣 계수는 0.445이다.

visualize_silhouette를 이용해 실루엣 스코어를 계산하고 군집을 시각화 해본 결과 정규화를 한쪽이 하지 않은 쪽보다 실루엣 계수가 작게 나타났다. 그러나 그 차이가 0.001로 매우 작기 때문에 큰 판별력을 가진다고 볼 수 없었다. 따라서 추가적으로 inertia를 계산했다.
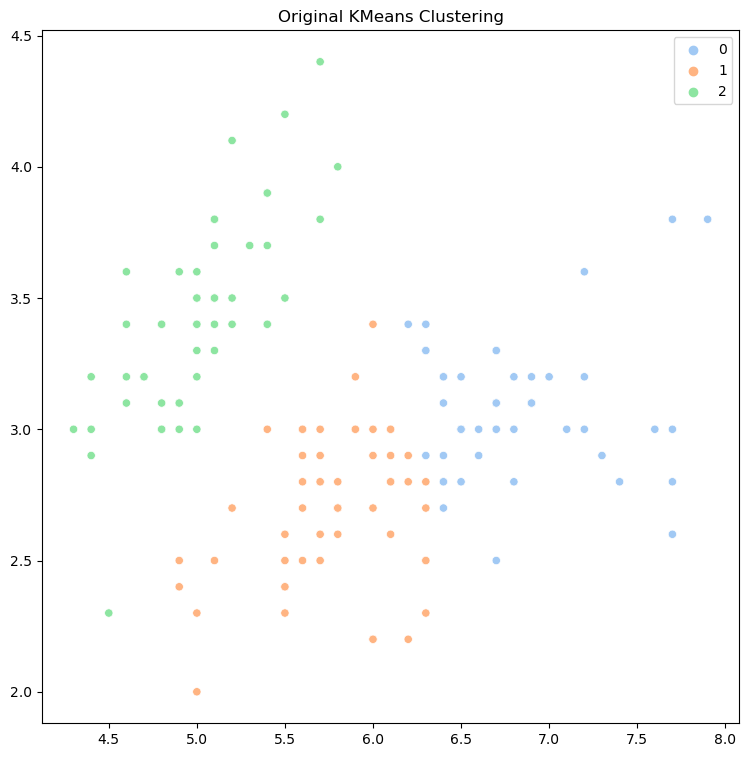
- 클러스터의 결과를 시각화 한다. (seaborn scatter plot)

plt.figure(figsize=(18,6))
plt.subplot(1,3,1)
# 최종 군집화 모델 scatter plot으로 표현하기
sns.scatterplot(x= X, y = y, hue = labels, palette='pastel')
plt. title('Original KMeans Clustering')
plt.subplot(1,3,2)
sns.scatterplot(x=X, y=y, hue = iris_y, palette = 'pastel' )
plt.title('Original')
plt.subplot(1,3,3)
# 최종 군집화 모델 scatter plot으로 표현하기
sns.scatterplot(x= X_mm_sc, y = y_mm_sc, hue = labels_mm, palette='pastel')
plt. title('MinMax Scaled KMeans Clustering')제출답안
# 데이터 불러오기
iris = load_iris()
iris_X, iris_y = iris.data, iris.target
# 스케일링 vs. 오리지널
from sklearn.preprocessing import MinMaxScaler
mm_sc = MinMaxScaler()
iris_X_mm_sc = mm_sc.fit_transform(iris_X)
# array를 펴주기
# 데이터의 첫번째 특성을 X축
X = np.array(iris_X).T[0]
X_mm_sc = np.array(iris_X_mm_sc).T[0]
# 두번째 특성을 Y축
y = np.array(iris_X).T[1]
y_mm_sc = np.array(iris_X_mm_sc).T[1]
# 라이브러리 불러오기
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# KMeans Clustering
kmeans = KMeans(n_clusters = 3, init = 'k-means++', random_state= 42)
kmeans_mm_sc = KMeans(n_clusters = 3, init = 'k-means++', random_state= 42)
# fitting
kmeans.fit(iris_X)
kmeans_mm_sc.fit(iris_X_mm_sc)
# 평가하기
X_features = np.column_stack((X,y))
X_features_mm = np.column_stack((X_mm_sc,y_mm_sc))
labels = kmeans.fit_predict(X_features)
labels_mm = kmeans_mm_sc.fit_predict(X_features_mm)
print(f'모델의 inertia는 {kmeans.inertia_ : .3f}이고, 실루엣 계수는 {silhouette_score(X_features, labels).round(3)}입니다.')
## 모델의 inertia는 37.051이고, 실루엣 계수는 0.445입니다.
print(f'정규화된 모델의 inertia는 {kmeans_mm_sc.inertia_ : .3f}이고, 실루엣 계수는 {silhouette_score(X_features_mm, labels_mm).round(3)}입니다.')
## 정규화된 모델의 inertia는 4.115이고, 실루엣 계수는 0.444입니다.
# scatter plot 그리기
sns.scatterplot(x= X, y = y, hue = labels, palette='pastel')
plt. title('Original KMeans Clustering')6. 딥러닝을 이용하여 MNIST 데이터를 분류하세요
- 본인만의 신경망을 구축하세요
- 학습하고 정확도(accuracy)를 계산하세요.
풀이과정
- 데이터 불러오기/ train, test 데이터 나누기
- 정규화 진행 : 0 ~ 1 사이 값으로
- 함수 불러오고 fitting하기
- Dense 를 사용하기 위해서 2차원 데이터를 1차원으로 Flatten
- 레이어, 히든레이어 , output 레이어 추가
- compile(분류에서는 무조건 cross entropy loss로 사용)
- evaluate
제출답안
# 데이터 불러오기
from tensorflow.keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 정규화 진행
X_train, y_train = X_train/255., y_train/255.
X_test, y_test = X_test/255., y_test/255.
# tensorflow 라이브러리 불러오기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
# Sequential 모델 초기화
model = Sequential()
model.add(Flatten(input_shape=[28, 28])) # 1차원 배열로 펼쳐주기
model.add(Dense(128, activation="relu"))
model.add(Dense(128, activation="relu"))
model.add(Dense(10, activation="softmax")) # 분류인 경우 맨 마지막 activation = softmax
# compile
model.compile(loss="sparse_categorical_crossentropy", #분류에서는 무조건 loss를 crossentropy를 사용
optimizer="sgd",
metrics=["accuracy"])
model.fit(X_train, y_train, epochs=20, validation_data=(X_test, y_test))
# evaluate
model.evaluate(X_test, y_test)
## model.evaluate(X_test, y_test)'📒 Today I Learn > 🐍 Python' 카테고리의 다른 글
| 머신러닝 특강 #3 군집화(Clustering) (0) | 2024.06.15 |
|---|---|
| 머신러닝 특강 #2 회귀(Regression) (0) | 2024.06.15 |
| 머신러닝의 이해와 라이브러리 활용 (7) 딥러닝 (1) | 2024.06.13 |
| 머신러닝 특강 #1 분류(Clasification) (0) | 2024.06.12 |
| 머신러닝의 이해와 라이브러리 활용 (6) 비지도학습 (0) | 2024.06.11 |